






SiFive 博客
来自 RISC-V 专家的最新洞察与深度技术解析

Introducing the Latest SiFive® Intelligence™ X280 Processor Innovation - the Vector Coprocessor Interface Extension (VCIX)
In June 2022, SiFive released an enhanced version of the market-leading SiFive® Intelligence™ X280 processor to take a further leap in performance for AI inference, image processing, and datacenter applications.
Alongside exciting new features including multi-cluster and SiFive WorldGuard trusted protection, the X280 now includes VCIX, SiFive’s new vector coprocessor accelerator interface, improving power and area efficiency, simplifying designs, and shortening design times.
The X280 shares equal success as a standalone processor as it does as a companion processor (to, for example, a custom accelerator) due to the broad range of applications that can benefit from its unique feature set that offers superior performance from the combined scalar and vector compute capabilities.
Modern workloads and applications often require the highest performance, but within a constrained power environment. Due to the excellent vector compute capabilities offered by the standard RISC-V Vector ISA and SiFive Intelligence Extensions, designers have been able to consolidate various specialized DSP accelerator functionality into a single X280 processor design thus maintaining a simpler system design and ease of programming, while still achieving the required performance and efficiency goals.
In certain situations, such as workloads requiring highly intensive computation on vector data, designers still require the use of heavily optimized custom accelerators to offload these tasks from the main processor. The challenge with this approach is that the custom accelerator needs to be designed to co-exist with the main processor, with some subtle design consequences in that the accelerator:
- will require access to, and use of an SoC system bus (for data transfers), potentially causing bus latency issues
- may need its own cache system or tightly coupled memory, for maintaining peak performance, with an associated increase in chip area
often requires a separate proprietary toolchain for programming, along with the separation of algorithm tasks increasing design time and reducing ease of programmability
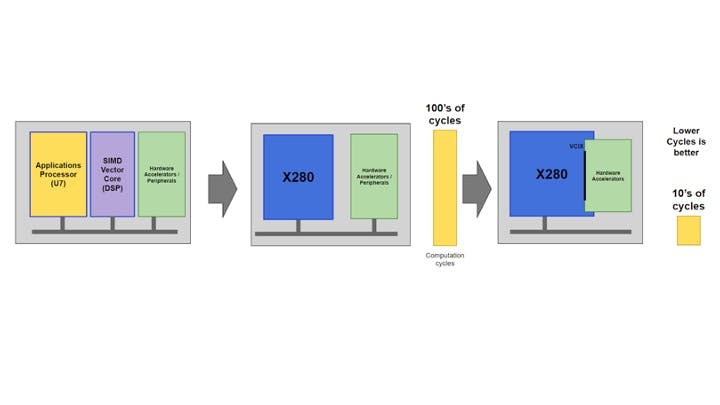 The SiFive Vector Coprocessor Interface Extension (VCIX) is a vector instruction-mapped interface, enabling a direct connection between the X280 vector ALU to a custom accelerator, allowing custom vector instructions to be executed on the accelerator from the vector pipeline. The custom vector instructions are executed from the standard SiFive software flow, utilizing the vector pipeline, with access to the full vector register set.
The SiFive Vector Coprocessor Interface Extension (VCIX) is a vector instruction-mapped interface, enabling a direct connection between the X280 vector ALU to a custom accelerator, allowing custom vector instructions to be executed on the accelerator from the vector pipeline. The custom vector instructions are executed from the standard SiFive software flow, utilizing the vector pipeline, with access to the full vector register set.
This powerful capability has many benefits to both hardware designers and software programmers as it can share some of the key processor resources, such as the vector register bank, main processor caching architecture, and memory system:
- A reduction and streamlining in both the design and test effort that is required when developing a customer accelerator due to the simpler design considerations
- Higher system performance, due to the significant reduction of computation cycles needed for specialized workloads
- Improved power and area efficiency by using the custom accelerator only when required, without the additional system area overhead
- Easier to program, as custom vector instructions are executed from the standard SiFive software flow
Want to learn more? Contact us or access the other materials on our SiFive vectors page.
Andy Frame


Read more Insights from the RISC-V Experts

P570 Gen 3:系统视角

SiFive Performance™ P570 Gen 3 深度解析:面向下一代消费级与商用应用的高性能能效设计
